
Attack of the IT Zombies
Posted by JamesThis content is copyright dxw, republished with permission. Originally published at https://www.dxw.com/2022/07/legacy-tech-systems-are-like-the-walking-dead/
Legacy technology systems are like zombies.
Not because they shamble on slowly, seemingly unstoppable. Not because they keep popping back up again when you thought you’d killed them. And not even because of the unfortunate smell…
No, legacy systems are like zombies because they survive on brains.
Any institution that’s been around since before the Information Age (however you measure that) will have built up its processes and systems with people and paper.
If we were to draw this in a modern technical architecture diagram (I’m using the C4 model in PlantUML for these diagrams), it might look like this:
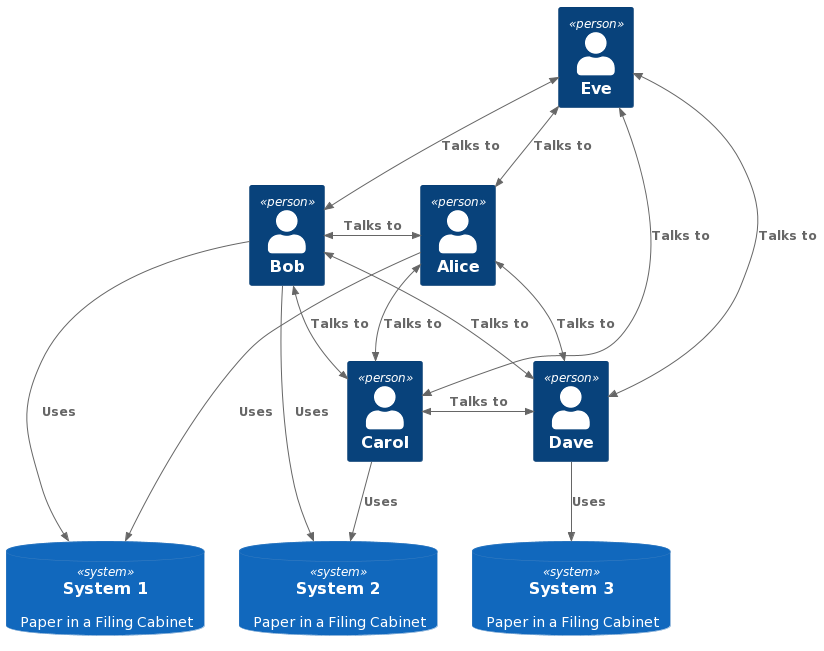
The systems storing the information are paper and filing cabinets, and all the data flows through the people and their tangled web of communications.
Moving into the digital realm, organisations took these processes and replaced the paper with computers. But all too often, the data flows weren’t changed too much – the information still flows between the systems via people’s brains.
Francis Irving gave a great talk about “digital paper” a few years back – this is where many institutions still are. Take a paper form, and put it on a computer. And this stuff really matters. Governments spend billions dealing with it, and legacy systems are often blamed for policy failures.
If we reflect that, our diagram now looks like this:
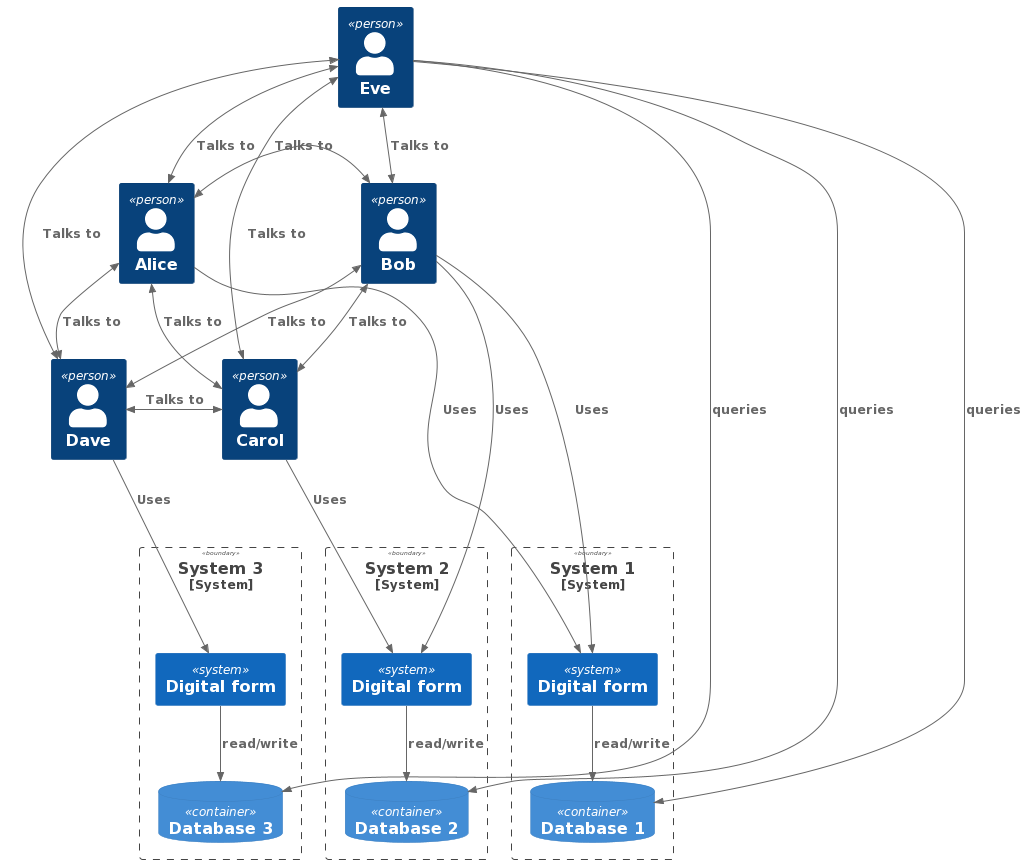
It’s OK, some new things are possible, like Eve digging into the databases directly for her audit information, but it’s not really a different system.
Now these diagrams are all well and good, but there’s something missing. Often we think of these old paper systems as simplistic, and our job with digital transformation is to make things smart.
But that’s not the case at all. Yes, paper itself is basic, but secretly every connection between data stores is mediated by an impossibly sophisticated pattern matching AI system, with its own attached data storage as well. These are very impressive machines, incredibly smart, but can be rather buggy, the I/O is somewhat slow, and the backup and failover options are frankly nowhere near up to scratch.
I mean, of course, human brains. Let’s redraw our diagram, treating our people as technical systems rather than humans, and peel back the layers so we can see inside the brains (ew).
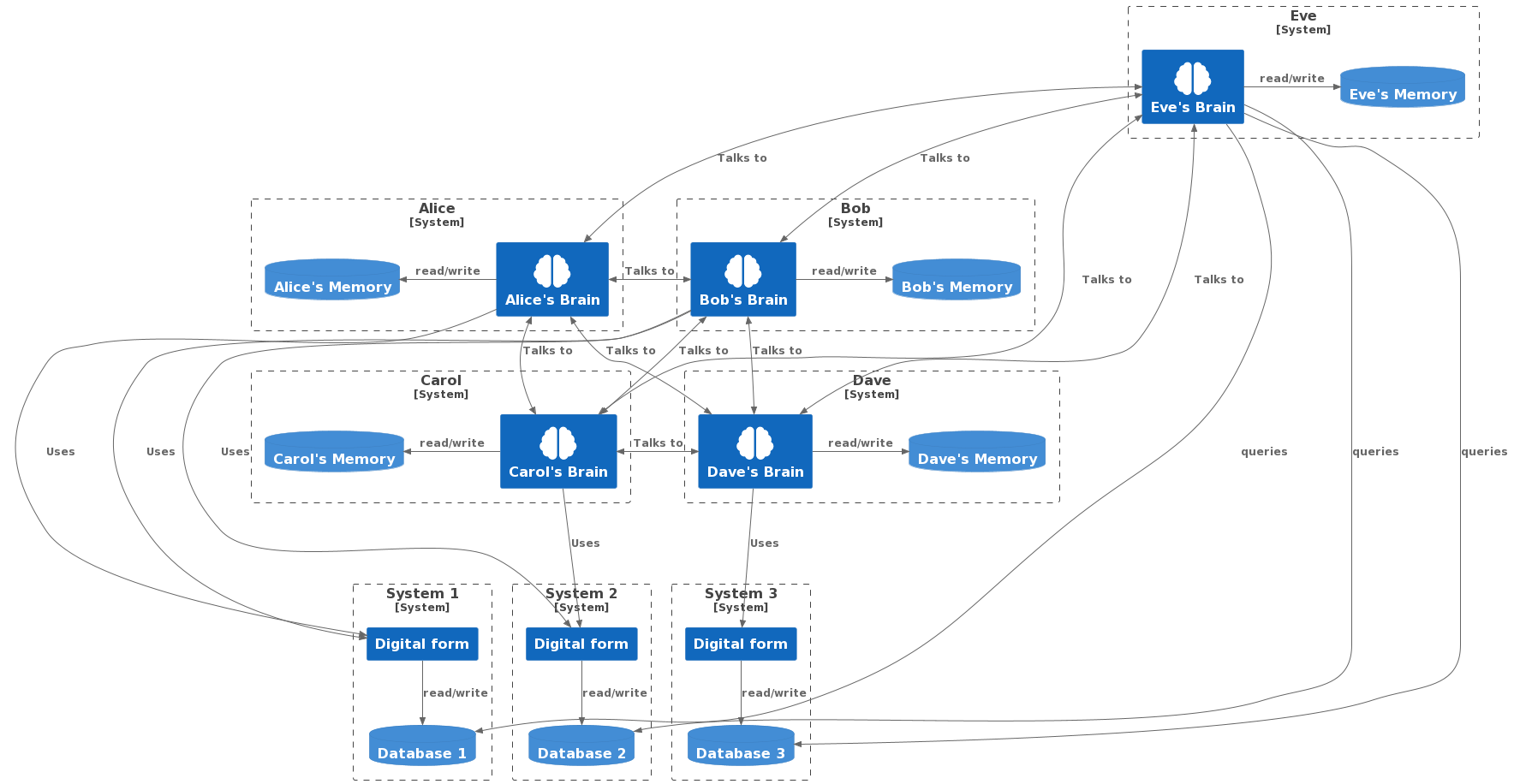
Now we have a truer view of the system, and we can see that if we want to do proper digital transformation of it, we have a problem. If we only think about changing the digital systems, which is the usual context, we’re leaving out a vast part of the existing system. And that part of the system will route around damage. It could treat our transformation as damage to its data stores, and instead find other options. For example, shadow systems and personal knowledge.
So, the job of digital transformation is not to make the system smarter. That’s impossible, given that the most complex machines in the universe are already an inherent part of it. What we want to do is move those machines to the edges, where they can do the work they’re uniquely capable of, and get all the stuff in the middle to work by itself.
So how do we do this? Well, how about we replace the meat computers with actual computers? Let’s start with some recent hotness, a bit of Robotic Process Automation (RPA) (or as we old hackers call it, scraping).
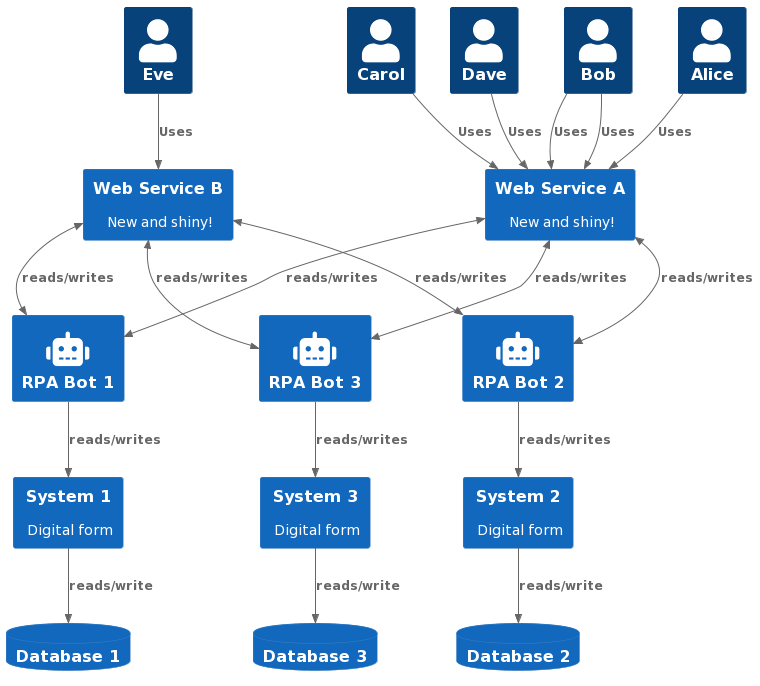
Now our digital systems are used by actual robots, and the humans are out at the edges where they can do uniquely human work like decision making, caring about people, solving unforeseeable problems, and watching Countdown with a cup of tea. There’s a whole seductive thing about automating these sorts of tasks instead of the stuff in the middle – for instance, AI that makes court judgments. This is The Wrong Approach, but that’s a whole other post. Let me know if you want me to write it sometime.
The problem with automating work that’s best for humans
There are 2 problems though. By moving the humans out to the edges, but not changing the existing digital systems, we’ve not dealt with some really important stuff. We think we’ve solved it, but we’ve ignored that web of links between the human systems, and we’ve ignored the shadow data stores that are inherent in each link.
No matter how clever our RPA tools are (and they’ll always be less clever than the humans), we’re going to lose something here if we just try to replace the people with actual AI systems. This leaves out many other implications of RPA, like embedding legacy IT even further into the organisation. There’s more about this in the MITSloan Management Review article Five Robotic Process Automation Risks to Avoid.
What we need to do
Instead, we have to fundamentally rethink our systems from the ground up. We can build new microservices in an agile way, delivering value quickly, but we have to build that on a thorough understanding of the true nature of the complete old system, and at least a rough plan for the new one. Ignoring those things, and assuming that service-focused User Research and Agile Development (wonderful as those things are) will solve the core issues, won’t work for an organisation-wide transformation; I like the term Architecture Nihilism for this approach.
We have to rethink the middle. We don’t want to make it smarter, because we inherently can’t. We have to make the middle less intelligent so we can move the smarts to the edge.
We need to look at what’s on the paper, and what’s in the shadow data stores inside the people. Then we need to combine those into a domain model, a coherent view of what the organisation knows, what the world looks like to the organisation. Then we need to remodel and design boundaries and connections between subdomains, and redesign our services taking into account all the official and unofficial communication paths in the old (human) systems.
Connecting the data within our domain comes next. If we have a record about a person in 2 different legacy systems, we have to be able to know that they match up. We can’t rely on our pattern matching AIs (humans) any more to tell us whether John Smith in system A is the same as John Q. Smith in system B based on a misspelt address and a birth date. We humans can handle that. Our databases can’t, unless they’re told explicitly.
Getting computers to do the boring stuff
This is where RPA can help – taking old data and extracting it, connecting it, and making those inferences is going to have to be done by someone. The right automated tooling can be really good at doing the bulk of that, with support from a human to make the tougher calls. It’s sometimes known as a Joint Cognitive System – the automation deals with the easy stuff, and bumps things it’s not sure about up to its human user for a judgement call.
But that’s best done as a one-time data transformation; we wouldn’t want to do that amount of processing every time we want to use some information in our system. For one thing, think of the environmental cost of all that excessive computation. And of course, it can’t get the information out of the shadow data stores in all those brains.
If we can transform our data and connections properly and intentionally, we can get to a state where the middle of our system is, frankly, really really… boring. And that’s a good thing. Computers are really good at boring, simple, repetitive tasks. We know exactly how to make them do those.
In the end, when we consider the whole system, maybe we can end up with something more like this (I know I’ve skipped ahead a huge amount here; this is a really complex problem solving process, which many others have explored better than I can here. Maybe next time):
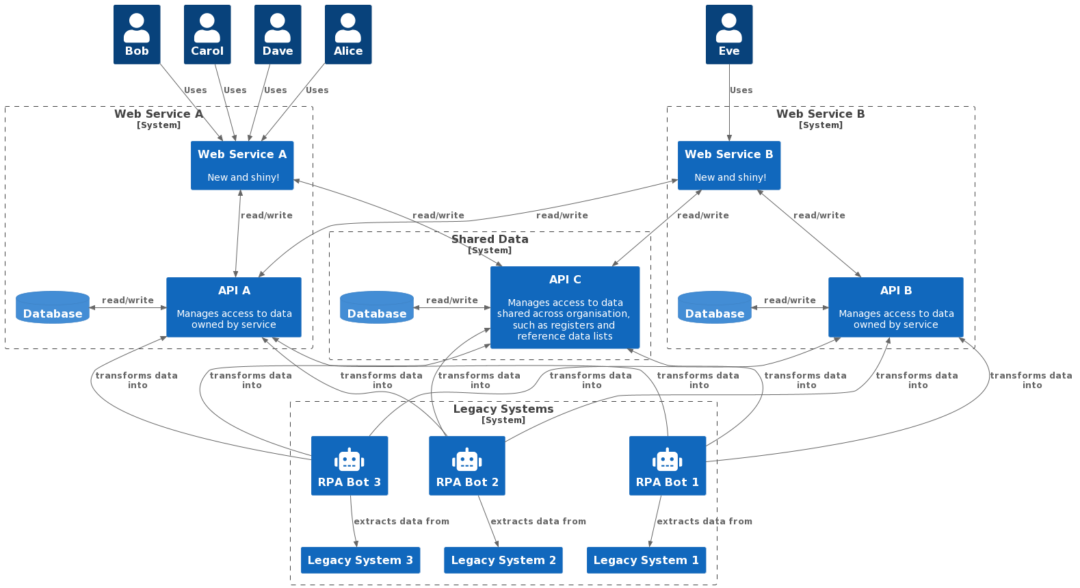
The transformed data and joined up domain means that the services can work together, and lets us move the human data storage into that coherent digital domain over time.
That finally lets us free up the people to work at the edge, being clever, compassionate, and caring (and talking to each other about Countdown) instead of using all that incredible brain power passing data around. If the data is connected, we can stop thinking about the people in the system as glitchy meat computers, and instead treat them as the wonderful, incredible, powerful things that they are, and let them do their best work.
Thanks to F, Joseph, Dom, and Chanelle and all the other smart dxw people who helped bounce around the ideas that fed into this. Love you all.
Comments
Add a comment